1. Introducción Los sistemas de localización de personas, tanto en interiores como en exteriores, han tomado un gran valor en la actualidad. Para la localización en exteriores, existe un sistema fiable y preciso cuyo uso se ha extendido, debido a una reducción de coste de los dispositivos necesarios para su funcionamiento. Este sistema se denomina GPS (Global Positioning System). Para la localización en interiores existen diversas ramas de desarrollo. La principal se denomina WPS (Wireless Positioning System) que basa la localización en las señales emitidas por diferentes puntos de acceso. |
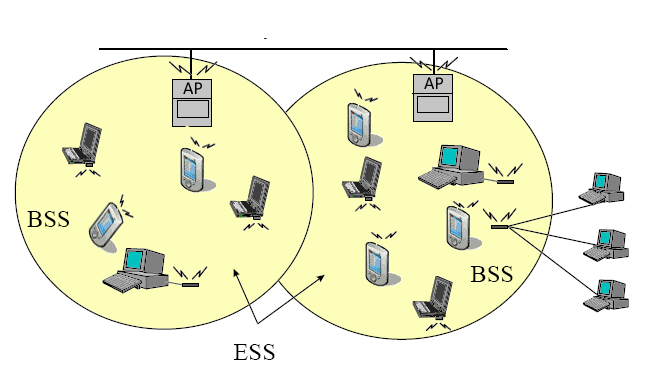
2. Conceptos Teóricos Una WLAN 802.11 está basada en una arquitectura celular. Cada celda, llamada BSS (Basic Service Set), está controlada por una estación base, denominada AP (Access Point). Toda la WLAN interconectada, incluyendo las diferentes celdas con sus respectivos APs, es tomada por los niveles superiores del modelo OSI como una única red 802, y se denomina ESS (Extended Service Set). |
Se basan en el teorema de Bayes, que define: P(H|E,c) se denomina probabilidad a posteriori. Es la probabilidad de que se cumpla la hipótesis H después de considerar el efecto de la evidencia E sobre el entorno (o contexto) c. |
| El concepto de probabilidad condicional es útil. Hay muchos casos en el mundo real donde la probabilidad de un suceso depende de la probabilidad de otros sucesos previos. Las reglas de suma y multiplicación de la teoría de la probabilidad pueden anticipar este factor de dependencia entre sucesos de forma exacta. Sin embargo, en muchos casos se convierte en un problema irresoluble. Por ejemplo, un escenario de diagnóstico de enfermedades con 5 variables discretas ( parámetros) sería programable. Sin embargo, un sistema experto con 37 variables ( parámetros) no sería una problema programable. Para el tratamiento de este tipo de problemas surgen las redes bayesianas. |
3. Técnicas y herramientas La elección de unas u otras técnicas y herramientas condicionan enormemente el desarrollo y la efectividad de un proyecto informático. Por ello debe llevar un tiempo el estudiar qué metodologías, lenguajes de programación, sistemas de gestión de datos, etc. Se deben utilizar para la realización del sistema. Con una buena elección se minimizará el tiempo necesario y el coste para la realización del proyecto y además se ayudará a proporcionar una mayor calidad al sistema. |
Se han utilizado los siguientes lenguajes de programación:
Las aplicaciones se ejecutan en los siguientes entornos:
|
La forma de acceso al driver de los dispositivos de red inalámbrica no fue trivial, convirtiéndose en una complicación significativa en el desarrollo del proyecto.
|
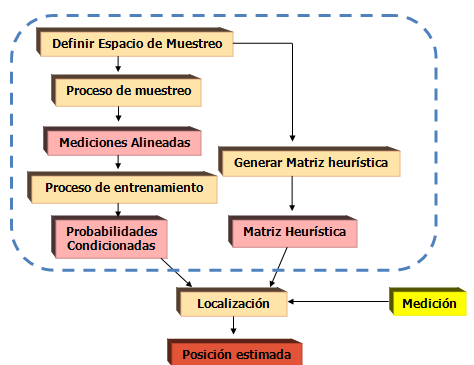
4. Aspectos relevantes del proyecto El flujo de trabajo que se siguió durante el desarrollo del proyecto se expone en la siguiente figura:
Se realizaron diez mediciones completas en cada celda del espacio de muestreo. Cada medición en una celda contiene diez muestras, distribuidas en las configuraciones representadas en las siguientes figuras |
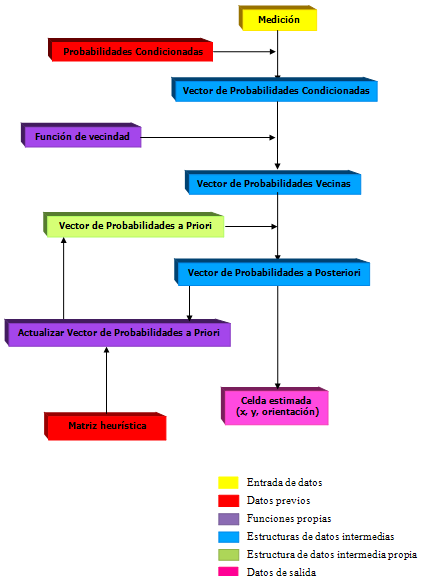
Este proceso genera la matriz heurística que será utilizada en el algoritmo de localización. Esta matriz indica la posibilidad que existe de pasar de una celda A a una celda B. Si la celda B está alejada de la celda A, la probabilidad de pasar de una celda a otra será menor que si la celda B es adyacente a la celda A. Será una matriz cuadrada de 90 × 90 (tantas como celdas se tienen en el espacio de muestreo). La función de dispersión es P = e^-0.3d (que se observa en la figura), donde es la distancia que separa dos celdas. Esta distancia se calcula teniendo en cuenta el número de celdas de separación y el número de cambios de orientación. Así, entre la celda (3,0,0) y la celda (0,0,6) la distancia sería de 4 (3 celdas de separación + 1 cambio de orientación). Cuando la distancia entre dos celdas supera el valor de 6, la probabilidad de pasar de una celda a la otra es 0, ya que es la distancia máxima entre dos mediciones consecutivas. |
|
|
|
Para el acceso a los drivers de las tarjetas de red inalámbricas de los dispositivos PDA utilizados nos basamos en:
|
|
Se realizaron estudios sobre la dependencia de la atenuación de la señal respecto a determinados factores como:
|
5. Conclusiones Se ha desarrollado un algoritmo de localización con una eficiencia adecuada, basándose en una optimización del método de muestreo, entrenamiento y del propio algoritmo. Se han realizado aplicaciones para dispositivos PDA que funcionan bajo diferentes sistemas operativos móviles y para diferentes dispositivos de red inalámbrica. |




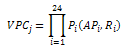
Alumno:
Jesús F. Rodríguez Aragón
Tutores:
D. Vidal Moreno Rodilla
Dª Belén Curto Diego
Junio 2007

